
Was ist generative KI: Terminologie
Einführung Generative KI ist ein dynamisches und sich schnell entwickelndes Feld innerhalb der künstlichen Intelligenz. Es konzentriert sich auf die Entwicklung von Algorithmen, die neuartige
ETL (Extract, Transform, Load) is vital for the success of most data engineering teams, and leveraging AWS enhances its significance. With the efficiency of ETL processes being crucial for these teams, it’s essential to thoroughly explore the complexities of ETL on AWS to elevate your data management practices.
Data Engineers and Data Scientists need effective methods for managing large datasets, making centralized data warehouses highly sought after.
Cloud computing has simplified the migration of data to the cloud, offering improved scalability, performance, robust integrations, and cost-effectiveness.
Additionally, it’s important to consider the vendor’s machine learning capabilities for predictive analytics.
The evolution of data integration with ETL has moved from high-cost, structured data stores to flexible, natural state storage with modifications made during read operations, thanks to the cloud’s adaptability.
Over the past three decades, data integration with ETL has undergone significant transformation. Historically, ETL processes were centered on structured data stores with substantial computing expenses. Today, cloud technology allows data to be stored in its natural state, with changes applied during read operations. This shift from the traditional method of data integration— which was heavily reliant on extensive computing processes and confined to structured data stores—demonstrates the impact of cloud agility on modern data management.
When discussing cloud computing, AWS (Amazon Web Services) is often the first name that comes to mind. As the leading cloud computing platform, AWS provides a wide array of services to businesses and developers, helping them maintain flexibility and efficiency. AWS’s clientele ranges from government agencies to multimillion-dollar startups, showcasing its broad applicability and reliability.
ETL, which stands for Extract, Transform, Load, involves extracting data from source systems, transforming it for analysis, and loading it into a target data system. Traditionally, ETL was conducted using on-premise tools and data warehouses. However, cloud computing has become the preferred method for ETL due to its numerous advantages.
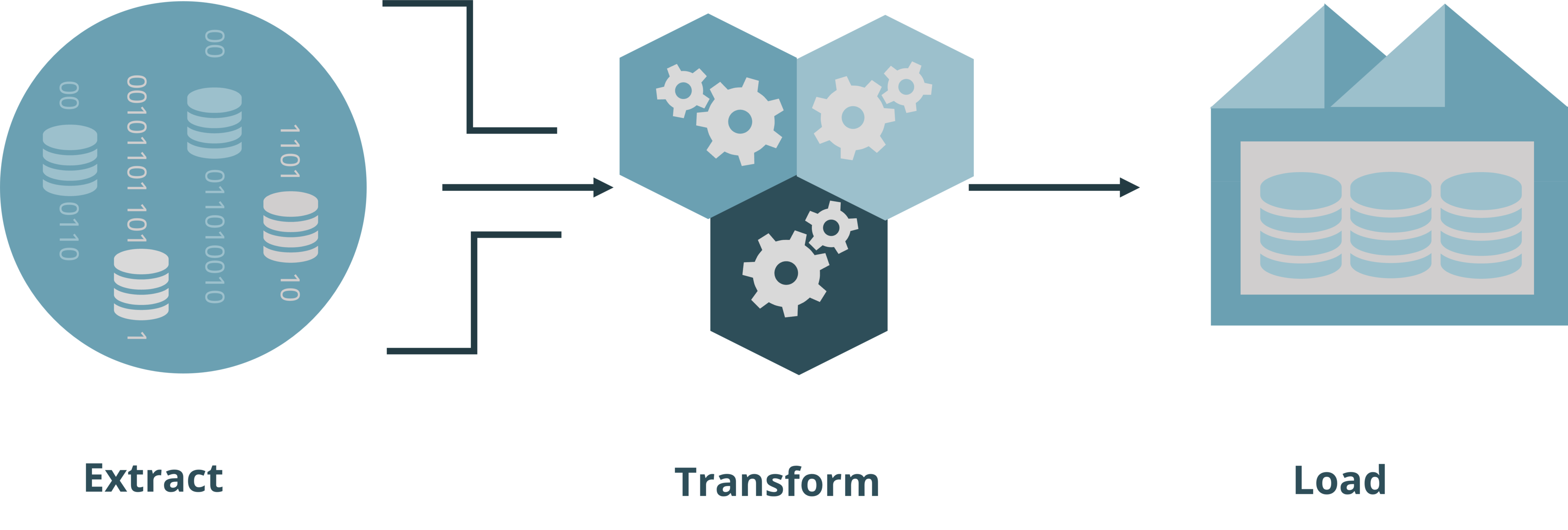
ETL Process Visualisation
One of the primary benefits of using ETL on AWS is its scalability.
AWS offers a scalable and cost-effective alternative to on-premise solutions, allowing businesses to adjust their resources based on demand, thereby managing data efficiently without unnecessary expenses.
Description: ETL Benefits
AWS provides a highly scalable environment for ETL processes. Companies can easily scale their ETL pipelines up or down according to the data volume, without the need for additional hardware or software. This flexibility ensures efficient resource management and cost savings.
AWS offers a comprehensive suite of services, including Amazon S3, AWS Glue, Amazon Redshift, and Amazon EMR, which can be used to build an ETL pipeline.
This variety allows businesses to choose the most suitable services for their needs and adapt their pipelines as those needs evolve.
With AWS’s pay-as-you-go pricing model, companies can avoid large upfront investments in expensive hardware and software.
This model makes AWS an affordable option for businesses of all sizes, allowing them to pay only for the resources they use.
AWS provides a robust infrastructure that enables rapid and efficient processing of large data volumes.
This high-performance capability is particularly beneficial for businesses that require near-real-time data processing.
AWS offers an intuitive interface for managing and monitoring ETL pipelines.
This user-friendly system facilitates team collaboration and maintenance, reducing the need for specialized skills and allowing teams to concentrate on core business activities.
AWS includes a variety of security features, such as encryption, access controls, and network isolation, ensuring that data is protected and secure at all times.
This robust security framework helps companies safeguard their sensitive information.
ETL architecture on AWS typically consists of three main components:
Source Data Store
Data Transformation Layer
Target Data Store
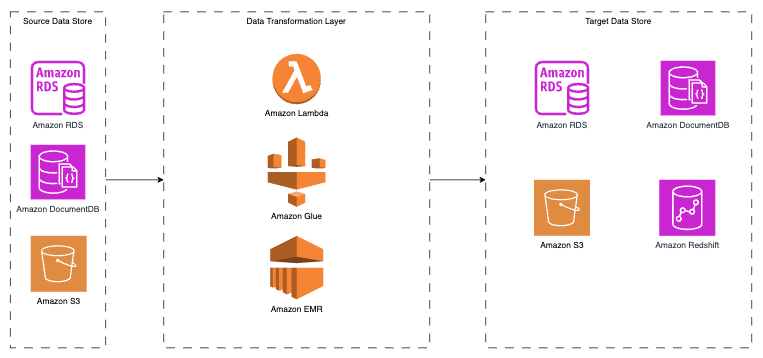
ETL Component Interactions in AWS
The source data store is where raw data is initially stored before being transformed and loaded into the target data store.
AWS offers a variety of relational and non-relational data stores that can serve as sources in an ETL pipeline. Examples of relational source data stores include Amazon Aurora and Amazon RDS, while Amazon DynamoDB and Amazon DocumentDB are examples of non-relational sources. Additionally, Amazon S3, an object storage service, can also be used as a source data store in ETL processes on AWS.
This layer is responsible for transforming raw data into a suitable format for loading into the target data store.
AWS provides several services for data transformation, including AWS Lambda, AWS Glue, and AWS EMR.
These services can be used to process and convert data to meet the required format for analysis and storage.
The target data store is where the transformed data is stored for analysis.
Similar to the source data stores, AWS offers both relational and non-relational options for target data stores.
Amazon Aurora and Amazon RDS serve as examples of relational target data stores, while Amazon DynamoDB and Amazon DocumentDB represent non-relational options. Additionally, Amazon S3 can be used as a target data store, and Amazon Redshift can be employed as a data warehousing solution for ETL processes on AWS.
To connect all the components of the ETL architecture on AWS, various integration services are available to orchestrate and automate the data flow.
Services like AWS EventBridge, AWS Step Functions, and AWS Batch facilitate seamless coordination between the different components in the ETL pipeline.
Overall, the ETL architecture on AWS streamlines the data processing workflow, allowing data analysts and data scientists to focus on analyzing data rather than processing it. This setup not only improves efficiency but also ensures that the data is ready for analysis in a timely manner, enhancing the overall data management process.
AWS Glue is a serverless ETL (Extract, Transform, and Load) service provided by AWS. This fully managed and cost-effective solution allows you to categorize, clean, enrich, and transfer data from source systems to target systems efficiently.
AWS Glue simplifies the ETL process by automating the tasks of cataloging, preparing, and cleaning data, enabling analysts to focus on data analysis rather than data wrangling. It includes a central metadata repository known as the Glue catalog and generates Scala or Python code for ETL processes.
Additionally, it offers features for job monitoring, scheduling, and metadata management, eliminating the need for infrastructure management as AWS handles it.
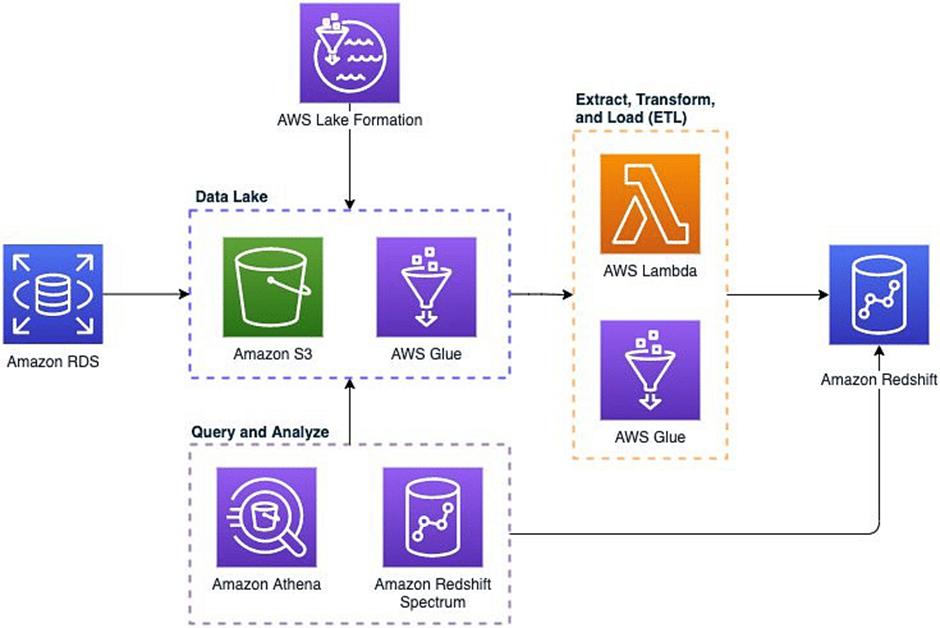
Simple AWS Glue Pipeline
AWS Glue provides an intuitive console for discovering, transforming, and querying data, making it ideal for working with structured and semi-structured data.
The console also allows you to edit and run ETL scripts in real-time, further streamlining the data transformation process.
Create a Data Catalog: The AWS Glue Data Catalog acts as a centralized repository for metadata about your data assets, such as data sources, transformations, and target destinations. To create a Data Catalog, specify the data stores and data formats you intend to use. This can be done manually or through AWS Glue’s automatic schema discovery feature.
Create a Crawler: A crawler in AWS Glue automatically discovers the schema of your data sources and generates the necessary metadata in the Data Catalog. The crawler also detects any schema changes and updates the metadata accordingly, ensuring that your data catalog remains accurate and up-to-date.
Create a Glue Job: A Glue job is a script that defines the transformation logic for your data. You can write the job in Scala or Python using AWS Glue’s built-in libraries or pre-built templates to perform ETL processes.
Define Data Transformations: Specify the data transformations by writing a Python or Scala script and uploading it to the job. This script will contain the logic for the data transformations and will be executed when the job runs.
Schedule the Job: Schedule the job to run at regular intervals by going to the „Triggers“ section of the AWS Glue console and creating a new trigger. Set the schedule for the trigger and select the job you want it to execute.
Monitor and Debug the Job: Use AWS Glue’s monitoring and logging tools to track the progress of the job. If any errors or issues arise during the ETL process, use the debugger to troubleshoot and resolve them.
By following these steps, you can effectively create an ETL pipeline using AWS Glue to extract, transform, and load data from various sources into a centralized data warehouse.
This streamlined process allows for efficient data management and enhances the ability to perform data analysis and make data-driven decisions.
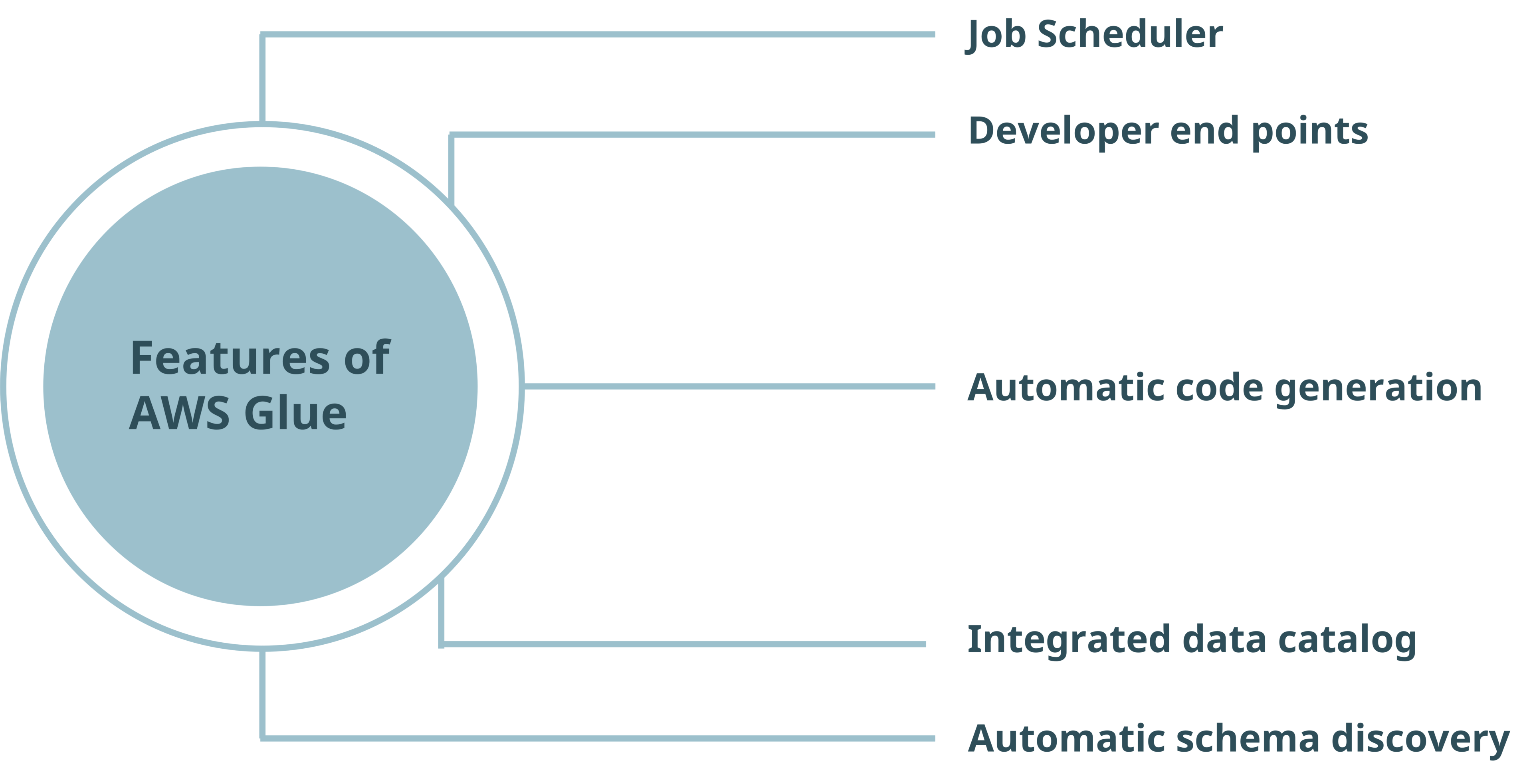
Serverless and Fully Managed: AWS Glue eliminates the need for managing underlying infrastructure, as AWS takes care of it.
Automated Metadata Management: The Glue catalog stores and manages metadata, making data discovery and management more efficient.
Code Generation and Real-Time Editing: AWS Glue generates ETL scripts in Scala or Python, which can be edited and executed in real-time through the console.
Integration and Compatibility: AWS Glue works seamlessly with other AWS services, enhancing data integration and transformation workflows.
AWS Glue Pipeline Benefits
The process of creating an ETL pipeline on AWS, specifically using AWS Glue, offers a robust solution for managing and transforming data efficiently.
AWS Glue simplifies the traditionally complex ETL tasks through its serverless architecture, which includes automated data discovery, transformation, and loading capabilities. By establishing a Glue Crawler to identify data sources and creating Glue Jobs to define transformation logic, organizations can streamline their data processing workflows.
The flexibility of AWS Glue in handling various data formats and sources, combined with its scalability, cost-effectiveness, and powerful monitoring tools, makes it an invaluable asset for data engineers and scientists. This allows them to focus more on data analysis and insights rather than the intricacies of data wrangling.
Overall, leveraging AWS Glue for ETL processes can significantly enhance data management, improve operational efficiency, and support data-driven decision-making in a scalable and secure environment.

Einführung Generative KI ist ein dynamisches und sich schnell entwickelndes Feld innerhalb der künstlichen Intelligenz. Es konzentriert sich auf die Entwicklung von Algorithmen, die neuartige

Der Kunde. Die Bank eines großen deutschen Automotive OEMs wickelt Leasing und andere Finanzierungsmodelle des OEMs ab. Sie unterliegt der Deutschen sowie der Europäischen Bankenaufsicht und
Der Kunde. Das Ministerium des Inneren des Landes Brandenburg / MIK trägt eine Vielzahl zentraler Aufgaben, die von Querschnittsfunktionen wie Organisation und Vermessungsangelegenheiten bis hin

Der Kunde. Die PD – Berater der öffentlichen Hand GmbH ist eine Partnerschaftsgesellschaft, die sich auf die Beratung öffentlicher Institutionen spezialisiert hat. Als Inhouse-Gesellschaft unterstützt

Der Kunde. CARIAD ist die Software- und Technologieeinheit des Volkswagen-Konzerns, die 2020 gegründet wurde, um die Digitalisierung und Vernetzung von Fahrzeugen voranzutreiben. Mit Fokus auf

Der Kunde. Die Volkswagen AG ist ein weltweit führender Automobilhersteller, der eine breite Palette von Fahrzeugen unter verschiedenen Marken wie Volkswagen, Audi und Porsche produziert.

